 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning via Self-Distillation
Jan 28, 2026Large language models are increasingly post-trained with reinforcement learning in verifiable domains such as code and math. Yet, current methods for reinforcement learning with verifiable rewards (RLVR) learn only from a scalar outcome reward per attempt, creating a severe credit-assignment bottleneck. Many verifiable environments actually provide rich textual feedback, such as runtime errors or judge evaluations, that explain why an attempt failed. We formalize this setting as reinforcement learning with rich feedback and introduce Self-Distillation Policy Optimization (SDPO), which converts tokenized feedback into a dense learning signal without any external teacher or explicit reward model. SDPO treats the current model conditioned on feedback as a self-teacher and distills its feedback-informed next-token predictions back into the policy. In this way, SDPO leverages the model's ability to retrospectively identify its own mistakes in-context. Across scientific reasoning, tool use, and competitive programming on LiveCodeBench v6, SDPO improves sample efficiency and final accuracy over strong RLVR baselines. Notably, SDPO also outperforms baselines in standard RLVR environments that only return scalar feedback by using successful rollouts as implicit feedback for failed attempts. Finally, applying SDPO to individual questions at test time accelerates discovery on difficult binary-reward tasks, achieving the same discovery probability as best-of-k sampling or multi-turn conversations with 3x fewer attempts.
Safe Exploration via Policy Priors
Jan 27, 2026Safe exploration is a key requirement for reinforcement learning (RL) agents to learn and adapt online, beyond controlled (e.g. simulated) environments. In this work, we tackle this challenge by utilizing suboptimal yet conservative policies (e.g., obtained from offline data or simulators) as priors. Our approach, SOOPER, uses probabilistic dynamics models to optimistically explore, yet pessimistically fall back to the conservative policy prior if needed. We prove that SOOPER guarantees safety throughout learning, and establish convergence to an optimal policy by bounding its cumulative regret. Extensive experiments on key safe RL benchmarks and real-world hardware demonstrate that SOOPER is scalable, outperforms the state-of-the-art and validate our theoretical guarantees in practice.
Latent Causal Diffusions for Single-Cell Perturbation Modeling
Jan 20, 2026Perturbation screens hold the potential to systematically map regulatory processes at single-cell resolution, yet modeling and predicting transcriptome-wide responses to perturbations remains a major computational challenge. Existing methods often underperform simple baselines, fail to disentangle measurement noise from biological signal, and provide limited insight into the causal structure governing cellular responses. Here, we present the latent causal diffusion (LCD), a generative model that frames single-cell gene expression as a stationary diffusion process observed under measurement noise. LCD outperforms established approaches in predicting the distributional shifts of unseen perturbation combinations in single-cell RNA-sequencing screens while simultaneously learning a mechanistic dynamical system of gene regulation. To interpret these learned dynamics, we develop an approach we call causal linearization via perturbation responses (CLIPR), which yields an approximation of the direct causal effects between all genes modeled by the diffusion. CLIPR provably identifies causal effects under a linear drift assumption and recovers causal structure in both simulated systems and a genome-wide perturbation screen, where it clusters genes into coherent functional modules and resolves causal relationships that standard differential expression analysis cannot. The LCD-CLIPR framework bridges generative modeling with causal inference to predict unseen perturbation effects and map the underlying regulatory mechanisms of the transcriptome.
Efficient Personalization of Generative Models via Optimal Experimental Design
Dec 22, 2025Preference learning from human feedback has the ability to align generative models with the needs of end-users. Human feedback is costly and time-consuming to obtain, which creates demand for data-efficient query selection methods. This work presents a novel approach that leverages optimal experimental design to ask humans the most informative preference queries, from which we can elucidate the latent reward function modeling user preferences efficiently. We formulate the problem of preference query selection as the one that maximizes the information about the underlying latent preference model. We show that this problem has a convex optimization formulation, and introduce a statistically and computationally efficient algorithm ED-PBRL that is supported by theoretical guarantees and can efficiently construct structured queries such as images or text. We empirically present the proposed framework by personalizing a text-to-image generative model to user-specific styles, showing that it requires less preference queries compared to random query selection.
Stackelberg Learning from Human Feedback: Preference Optimization as a Sequential Game
Dec 18, 2025We introduce Stackelberg Learning from Human Feedback (SLHF), a new framework for preference optimization. SLHF frames the alignment problem as a sequential-move game between two policies: a Leader, which commits to an action, and a Follower, which responds conditionally on the Leader's action. This approach decomposes preference optimization into a refinement problem for the Follower and an optimization problem against an adversary for the Leader. Unlike Reinforcement Learning from Human Feedback (RLHF), which assigns scalar rewards to actions, or Nash Learning from Human Feedback (NLHF), which seeks a simultaneous-move equilibrium, SLHF leverages the asymmetry of sequential play to capture richer preference structures. The sequential design of SLHF naturally enables inference-time refinement, as the Follower learns to improve the Leader's actions, and these refinements can be leveraged through iterative sampling. We compare the solution concepts of SLHF, RLHF, and NLHF, and lay out key advantages in consistency, data sensitivity, and robustness to intransitive preferences. Experiments on large language models demonstrate that SLHF achieves strong alignment across diverse preference datasets, scales from 0.5B to 8B parameters, and yields inference-time refinements that transfer across model families without further fine-tuning.
Learning Soft Robotic Dynamics with Active Exploration
Oct 31, 2025Soft robots offer unmatched adaptability and safety in unstructured environments, yet their compliant, high-dimensional, and nonlinear dynamics make modeling for control notoriously difficult. Existing data-driven approaches often fail to generalize, constrained by narrowly focused task demonstrations or inefficient random exploration. We introduce SoftAE, an uncertainty-aware active exploration framework that autonomously learns task-agnostic and generalizable dynamics models of soft robotic systems. SoftAE employs probabilistic ensemble models to estimate epistemic uncertainty and actively guides exploration toward underrepresented regions of the state-action space, achieving efficient coverage of diverse behaviors without task-specific supervision. We evaluate SoftAE on three simulated soft robotic platforms -- a continuum arm, an articulated fish in fluid, and a musculoskeletal leg with hybrid actuation -- and on a pneumatically actuated continuum soft arm in the real world. Compared with random exploration and task-specific model-based reinforcement learning, SoftAE produces more accurate dynamics models, enables superior zero-shot control on unseen tasks, and maintains robustness under sensing noise, actuation delays, and nonlinear material effects. These results demonstrate that uncertainty-driven active exploration can yield scalable, reusable dynamics models across diverse soft robotic morphologies, representing a step toward more autonomous, adaptable, and data-efficient control in compliant robots.
Learning on the Job: Test-Time Curricula for Targeted Reinforcement Learning
Oct 06, 2025



Humans are good at learning on the job: We learn how to solve the tasks we face as we go along. Can a model do the same? We propose an agent that assembles a task-specific curriculum, called test-time curriculum (TTC-RL), and applies reinforcement learning to continue training the model for its target task. The test-time curriculum avoids time-consuming human curation of datasets by automatically selecting the most task-relevant data from a large pool of available training data. Our experiments demonstrate that reinforcement learning on a test-time curriculum consistently improves the model on its target tasks, across a variety of evaluations and models. Notably, on challenging math and coding benchmarks, TTC-RL improves the pass@1 of Qwen3-8B by approximately 1.8x on AIME25 and 2.1x on CodeElo. Moreover, we find that TTC-RL significantly raises the performance ceiling compared to the initial model, increasing pass@8 on AIME25 from 40% to 62% and on CodeElo from 28% to 43%. Our findings show the potential of test-time curricula in extending the test-time scaling paradigm to continual training on thousands of task-relevant experiences during test-time.
Apertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
SonoGym: High Performance Simulation for Challenging Surgical Tasks with Robotic Ultrasound
Jul 01, 2025Ultrasound (US) is a widely used medical imaging modality due to its real-time capabilities, non-invasive nature, and cost-effectiveness. Robotic ultrasound can further enhance its utility by reducing operator dependence and improving access to complex anatomical regions. For this, while deep reinforcement learning (DRL) and imitation learning (IL) have shown potential for autonomous navigation, their use in complex surgical tasks such as anatomy reconstruction and surgical guidance remains limited -- largely due to the lack of realistic and efficient simulation environments tailored to these tasks. We introduce SonoGym, a scalable simulation platform for complex robotic ultrasound tasks that enables parallel simulation across tens to hundreds of environments. Our framework supports realistic and real-time simulation of US data from CT-derived 3D models of the anatomy through both a physics-based and a generative modeling approach. Sonogym enables the training of DRL and recent IL agents (vision transformers and diffusion policies) for relevant tasks in robotic orthopedic surgery by integrating common robotic platforms and orthopedic end effectors. We further incorporate submodular DRL -- a recent method that handles history-dependent rewards -- for anatomy reconstruction and safe reinforcement learning for surgery. Our results demonstrate successful policy learning across a range of scenarios, while also highlighting the limitations of current methods in clinically relevant environments. We believe our simulation can facilitate research in robot learning approaches for such challenging robotic surgery applications. Dataset, codes, and videos are publicly available at https://sonogym.github.io/.
Provable Maximum Entropy Manifold Exploration via Diffusion Models
Jun 18, 2025

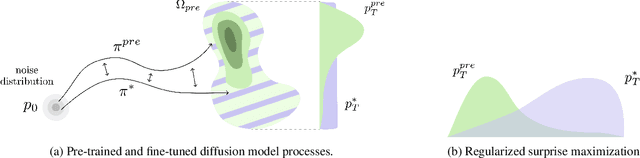

Exploration is critical for solving real-world decision-making problems such as scientific discovery, where the objective is to generate truly novel designs rather than mimic existing data distributions. In this work, we address the challenge of leveraging the representational power of generative models for exploration without relying on explicit uncertainty quantification. We introduce a novel framework that casts exploration as entropy maximization over the approximate data manifold implicitly defined by a pre-trained diffusion model. Then, we present a novel principle for exploration based on density estimation, a problem well-known to be challenging in practice. To overcome this issue and render this method truly scalable, we leverage a fundamental connection between the entropy of the density induced by a diffusion model and its score function. Building on this, we develop an algorithm based on mirror descent that solves the exploration problem as sequential fine-tuning of a pre-trained diffusion model. We prove its convergence to the optimal exploratory diffusion model under realistic assumptions by leveraging recent understanding of mirror flows. Finally, we empirically evaluate our approach on both synthetic and high-dimensional text-to-image diffusion, demonstrating promising results.